| This article originally appeared in Geospatial Solutions Magazine's Net Results column of May 1, 2003. Other Net Results articles about the role of emerging technologies in the exchange of spatial information are also online. | |
| 1. Introduction and Glossary 2. Data Flow 3. Indexing Challenge 4. Instant Messaging Conundrum | |
| The real-time indexing challenge A specialized storage format may solve the problem of irregular data flow, but how will tomorrow’s LBS providers overcome the performance challenges of a million users? When I was a little boy, my babysitters and I played a memory game called "Concentration." We would lay out a deck of cards upside down on the floor in a big grid and then take turns flipping over just two cards. If the cards matched, you got to keep them and pick again. If not, you had to turn them back over, hopefully memorizing their positions for later. The data in traditional spatial applications is like the cards in Concentration; it’s static and therefore easy to memorize, or, in database terminology, to index. Traditionally, databases answer queries quickly by checking an index. Rather than searching through all of a table’s millions of rows for the answer, database software checks the index to isolate a much smaller data subset and search only there for the proper candidates. In real-time applications, though, the data moves -- all at once! Imagine playing concentration when the cards change position randomly between turns. That’s what makes applications with large mobile datasets perform more slowly than traditional nonreal-time applications. The database software just can’t rebuild its spatial indexes fast enough, or often enough, if the whole dataset keeps changing. This problem becomes even more intractable if the number of changing datapoints is large (a telecommunications application, for instance, with millions of customers). Profilers. In response to this problem, a few companies, such as Apama (www. apama.com), iProx (www. iprox.com), and Telcontar (www. telcontar.com), offer software that, instead of storing, indexing, and querying the incoming real-time data, stores and indexes the queries themselves in a database and then lets the real-time data filter through the queries or "profiles." When real-time data matches the query criteria, Apama’s software sends a message (see Figure 4). For instance, a flow of vehicle locations can be checked to see if any individual car is within a predefined static region using a query such as "child’s car intersects school parking lot polygon." |
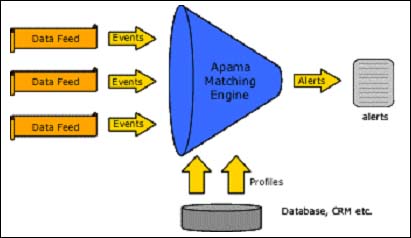
Figure 4: This conceptual diagram shows Apama’s solution to the heavy flow of real-time data. The software checks for relationships as the data passes by, sending a message (alert) if a preestablished condition (profile) is met. |
|
Although this clever solution solves mobile-to-static spatial problems, it
doesn’t seem to solve mobile-tomobile ones. Because it does not store the
incoming real-time data, Apama’s approach cannot reference one event’s
relationship to another. To compare the location of one individual car to
another (mobile-to-mobile) requires scanning the entire collection of cars
at that moment. In other words, it requires a real-time spatial index. Darn.
Industry buzz claims that, though not yet available, mobile-to-mobile indexing
solutions are in development. IBM’s (www.ibm.com) LBS lab in Oakland, California,
reports storing real-time data in a memory cache rather than in a database on
disk, which dramatically improves performance. To index the moving data points,
IBM developers have tested a space-partitioning in-memory structure that
successfully indexes spatial relationships in a collection of 1 million
randomly moving points. IBM’s Virtual Table Interface (VTI) software makes
this real-time memory cache appear to be just another database table to the
casual spatial query language user.
|
| 1. Introduction and Glossary 2. Data Flow 3. Indexing Challenge 4. Instant Messaging Conundrum |
|
|